Comprehensive Linguistic-Visual Composition Network for Image Retrieval
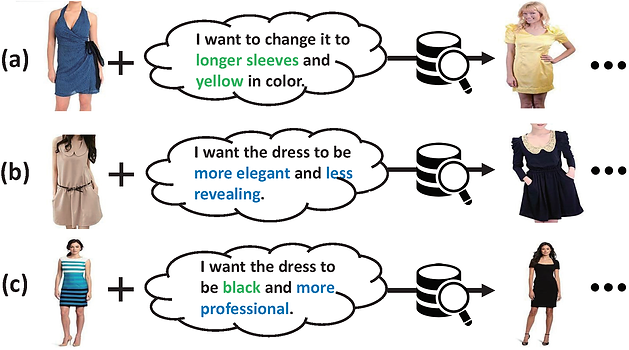
Figure1: Three examples of composing text and image for image retrieval.
Composing text and image for image retrieval (CTI-IR) is a new yet challenging task, for which the input query is not the conventional image or text but a composition, i.e., a reference image and its corresponding modification text. The key of CTI-IR lies in how to properly compose the multi-modal query to retrieve the target image. In a sense, pioneer studies mainly focus on composing the text with either the local visual descriptor or global feature of the reference image. However, they overlook the fact that the text modifications are indeed diverse, ranging from the concrete attribute changes, like “change it to long sleeves”, to the abstract visual property adjustments, e.g., “change the style to professional”. Thus, simply emphasizing the local or global feature of the reference image for the query composition is insufficient. In light of the above analysis, we propose a Comprehensive Linguistic-Visual Composition Network (CLVC-Net) for image retrieval. The core of CLVC-Net is that it designs two composition modules: fine-grained local-wise composition module and fine-grained global-wise composition module, targeting comprehensive multi-modal compositions. Additionally, a mutual enhancement module is designed to promote local-wise and global-wise composition processes by forcing them to share knowledge with each other. Extensive experiments conducted on three real-world datasets demonstrate the superiority of our CLVC-Net.